Machine Learning (Học máy) là một chủ đề đang “nóng” hơn bao giờ hết, thường được nhắc đến cùng với Trí tuệ nhân tạo. Nó đang được ứng dụng rộng rãi trong hầu hết mọi lĩnh vực ở thời điểm hiện tại.
Trong bài viết này của Dầu gội dầu, chúng ta sẽ cùng tìm hiểu Machine Learning là gì, các khái niệm cơ bản của nó và lý do vì sao nó lại trở nên phổ biến đến vậy.
I. Định nghĩa về Machine learning
Hiện nay, có vô vàn định nghĩa về Machine Learning (ML), và nếu bạn đã từng tìm kiếm trên Google, chắc hẳn bạn cũng nhận ra điều này. Tôi đã tổng hợp và đúc kết lại thành một khái niệm đơn giản như sau:
Machine Learning, hay còn gọi là máy học, là một lĩnh vực nghiên cứu thuộc nhánh của trí tuệ nhân tạo (AI). Nó cho phép máy tính tự cải thiện khả năng của mình dựa trên các dữ liệu mẫu (training data) hoặc thông qua kinh nghiệm (những gì đã được học). Nhờ vậy, Machine Learning có thể tự dự đoán hoặc đưa ra quyết định mà không cần được lập trình cụ thể cho từng trường hợp.
Các bài toán trong Machine Learning thường được phân loại thành hai dạng chính: dự đoán (prediction) và phân loại (classification). Ví dụ về bài toán dự đoán là dự đoán giá nhà, giá xe; còn bài toán phân loại bao gồm nhận diện chữ viết tay hay nhận diện đồ vật.
II. Cách hoạt động của Machine learning
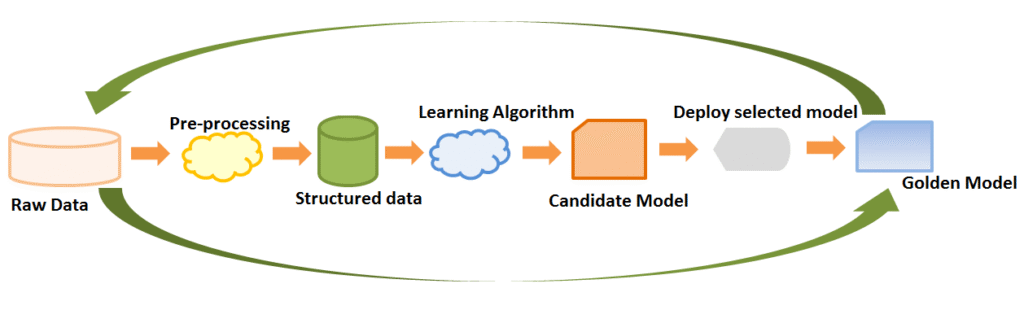
Để hiểu rõ cách làm việc với Machine Learning, bạn có thể tham khảo quy trình Machine Learning Workflow dưới đây (hãy xem sơ đồ minh họa bên dưới). Cụ thể, quy trình này bao gồm các bước sau:
1. Data Collection (Thu Thập Dữ Liệu)
Để máy tính có thể “học”, bạn cần có một bộ dữ liệu (dataset). Bạn có thể tự thu thập dữ liệu hoặc sử dụng các bộ dữ liệu đã được công bố. Điều quan trọng là phải thu thập dữ liệu từ nguồn chính thống để đảm bảo độ chính xác, giúp máy học hiệu quả và đạt kết quả cao.
2. Preprocessing (Tiền Xử Lý Dữ Liệu)
Bước này nhằm chuẩn hóa dữ liệu bằng cách loại bỏ các thuộc tính không cần thiết, gán nhãn, mã hóa một số đặc trưng, trích xuất đặc trưng và rút gọn dữ liệu nhưng vẫn giữ được thông tin quan trọng. Đây là bước tốn thời gian nhất, tỷ lệ thuận với khối lượng dữ liệu bạn có. Thông thường, bước thu thập và tiền xử lý dữ liệu (bước 1 và 2) thường chiếm hơn 70% tổng thời gian thực hiện dự án Machine Learning.
3. Training Model (Huấn Luyện Mô Hình)
Ở bước này, bạn sẽ huấn luyện mô hình của mình, tức là cho nó học từ bộ dữ liệu đã được thu thập và xử lý ở hai bước đầu.
4. Evaluating Model (Đánh Giá Mô Hình)
Sau khi huấn luyện xong, bạn cần sử dụng các độ đo phù hợp để đánh giá chất lượng của mô hình. Tùy thuộc vào độ đo được sử dụng, mô hình sẽ được đánh giá là tốt hay không. Một mô hình được coi là tốt nếu đạt độ chính xác trên 80%.
5. Improve (Cải Thiện)
Nếu mô hình chưa đạt độ chính xác như mong đợi sau khi đánh giá, bạn cần huấn luyện lại. Quá trình này sẽ lặp lại từ bước 3 cho đến khi mô hình đạt được độ chính xác kỳ vọng. Tổng thời gian của ba bước cuối cùng (huấn luyện, đánh giá và cải thiện) thường chỉ chiếm khoảng 30% tổng thời gian thực hiện.
III. Các loại Machine learning
Machine Learning có nhiều cách phân loại, nhưng phổ biến nhất là chia thành hai nhóm chính: Học có giám sát (Supervised Learning) và Học không giám sát (Unsupervised Learning).
Ngoài ra, còn có các dạng khác như:
- Học bán giám sát (Semi-supervised Learning)
- Học sâu (Deep Learning)
- Học củng cố/tăng cường (Reinforcement Learning)
Trong bài viết này, chúng ta sẽ tập trung vào hai phương pháp phân loại phổ biến nhất.
Học có Giám sát (Supervised Learning)
Supervised Learning là quá trình máy tính học từ dữ liệu đã được gán nhãn. Điều này có nghĩa là, với mỗi dữ liệu đầu vào (Xi), chúng ta đều có một kết quả hoặc nhãn tương ứng (Yi) đã biết trước. Máy sẽ học mối quan hệ giữa đầu vào và đầu ra này để đưa ra dự đoán cho dữ liệu mới.
Học không Giám sát (Unsupervised Learning)
Ngược lại, Unsupervised Learning là khi máy tính học trên dữ liệu chưa được gán nhãn. Các thuật toán Machine Learning sẽ tự tìm ra sự tương quan, cấu trúc, hoặc các mẫu ẩn trong dữ liệu. Mục tiêu là giúp máy tính có được “kiến thức” và hiểu biết về dữ liệu, từ đó có thể phân nhóm các dữ liệu tương tự lại với nhau (clustering) hoặc giảm số chiều dữ liệu (dimension reduction) để dễ dàng phân tích hơn.
IV. Các thuật ngữ cơ bản của Machine Learning
Để hiểu rõ hơn về Machine Learning, chúng ta cần nắm vững các khái niệm cơ bản sau:
1. Dataset
Dataset (còn được gọi là tập dữ liệu hoặc kho dữ liệu) là tập hợp các dữ liệu thô, chưa qua xử lý, được thu thập ở bước ban đầu. Một dataset sẽ bao gồm nhiều điểm dữ liệu (data point).
2. Data Point
Data point là một điểm dữ liệu, biểu thị cho một quan sát cụ thể. Mỗi data point chứa nhiều đặc trưng (features) hay thuộc tính khác nhau, có thể là dữ liệu số (numerical) hoặc dữ liệu phi số/phân loại (non-numerical/categorical) như chuỗi văn bản. Trong cấu trúc dữ liệu, mỗi data point thường được biểu diễn thành một dòng, và mỗi dòng có thể chứa một hoặc nhiều dữ liệu (tương ứng với các đặc trưng).
3. Training Data và Test Data
Thông thường, dataset sẽ được chia thành hai tập con: training data (dữ liệu huấn luyện) và test data (dữ liệu kiểm thử). Training data được dùng để huấn luyện mô hình, trong khi test data dùng để đánh giá khả năng dự đoán của mô hình. Trong một số bài toán, hai tập này đã được cung cấp sẵn, nhưng nếu chỉ có dataset ban đầu, bạn cần tự chia. Tỷ lệ phổ biến giữa tập huấn luyện và kiểm thử thường là 8:2.
4. Features Vector
Features vector (vector đặc trưng) là một vector biểu diễn cho mỗi điểm dữ liệu trong dataset. Mỗi vector có n chiều, tương ứng với n đặc trưng của điểm dữ liệu đó. Điều quan trọng là mỗi đặc trưng trong vector phải là dữ liệu số. Các mô hình Machine Learning chỉ có thể được huấn luyện từ các vector đặc trưng này, do đó dataset cần được chuyển đổi về dạng một tập hợp các vector đặc trưng.
5. Model
Model (mô hình) là các cấu trúc được sử dụng để huấn luyện trên training data theo một thuật toán cụ thể. Sau khi được huấn luyện, mô hình có khả năng dự đoán hoặc đưa ra các quyết định dựa trên những kiến thức mà nó đã học được từ dữ liệu.
V. Các ứng dụng của Machine learning
Machine Learning đang ngày càng trở nên phổ biến và được ứng dụng rộng rãi trong hầu hết các lĩnh vực của đời sống hiện đại, bao gồm:
- Tài chính – Ngân hàng: Dự đoán rủi ro tín dụng, phát hiện gian lận.
- Sinh học: Phân tích chuỗi gen, phát hiện bệnh.
- Nông nghiệp: Dự đoán năng suất cây trồng, quản lý dịch bệnh.
- Tìm kiếm, trích xuất thông tin: Cải thiện kết quả tìm kiếm, tự động hóa trích xuất dữ liệu.
- Tự động hóa: Tối ưu hóa quy trình sản xuất, điều khiển hệ thống.
- Robotics: Giúp robot học cách di chuyển, tương tác với môi trường.
- Hóa học: Thiết kế vật liệu mới, dự đoán tính chất hóa học.
- Mạng máy tính: Phát hiện tấn công mạng, tối ưu hóa lưu lượng.
- Khoa học vũ trụ: Phân tích dữ liệu thiên văn, tìm kiếm hành tinh mới.
- Quảng cáo: Nhắm mục tiêu quảng cáo, cá nhân hóa trải nghiệm người dùng.
- Xử lý ngôn ngữ tự nhiên: Dịch thuật, nhận diện giọng nói, chatbot.
- Thị giác máy tính: Nhận diện đối tượng, phân tích hình ảnh.
Và còn rất nhiều lĩnh vực khác mà Machine Learning có thể phát huy hiệu quả vượt trội, thậm chí còn hiệu quả hơn con người trong các nhiệm vụ cụ thể. Chính vì sự phổ biến và hiệu quả vượt trội này, việc bạn có kiến thức và học hỏi về Machine Learning chắc chắn sẽ là một lợi thế lớn trong kỷ nguyên công nghệ 4.0 hiện nay.
Như vậy, chúng ta đã cùng nhau tìm hiểu tổng quan về Machine Learning, từ định nghĩa cơ bản đến các khái niệm cốt lõi và những ứng dụng rộng rãi của nó. Nếu bạn thấy bài viết này hữu ích hoặc có bất kỳ đóng góp nào để nội dung được hoàn thiện hơn, đừng ngần ngại để lại bình luận phía dưới nhé!